7月25日消息,日前Meta正式发布了Llama 3.1开源大模型,以其庞大的参数量和卓越性能,首次在多项基准测试中击败了GPT-4o等业界领先的闭源模型。
允许开发者自由地进行微调、蒸馏,甚至在任何地方部署,这种开放性为AI技术的普及和创新提供了无限可能。
Llama 3.1支持128k的上下文长度和多语言能力,无论是在基本常识、可操作性还是数学、工具使用和多语言翻译方面,都展现出了行业领先的能力。
紧随其后,芯片巨头Intel迅速响应,宣布其AI产品组合已全面适配Llama 3.1,并针对Intel AI硬件进行了软件优化。
包括了数据中心、边缘计算以及客户端AI产品,确保用户能够在Intel平台上获得最佳的性能体验。
Intel的适配工作涵盖了PyTorch及Intel PyTorch扩展包、DeepSpeed、Hugging Face Optimum库和vLLM等,确保了从研发到部署的全流程支持。

目前,Intel AI PC及数据中心AI产品组合和解决方案已面向全新Llama 3.1模型实现优化,OPEA(企业AI开放平台)亦在基于Intel至强等产品上全面启用。
根据基准测试,在第五代Intel至强平台上以1K token输入和128 token输出运行80亿参数的Llama 3.1模型,可以达到每秒176 token的吞吐量,同时保持下一个token延迟小于50毫秒。
在配备了酷睿Ultra处理器和锐炫显卡的AI PC上,进行轻量级微调和应用定制比以往更加容易,并且AI工作负载可无缝部署于CPU、GPU以及NPU上,同时实现性能优化。
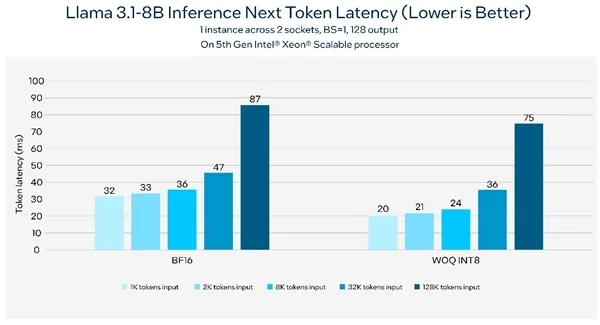
基于第五代Intel至强可扩展处理器的Llama 3.1推理延迟
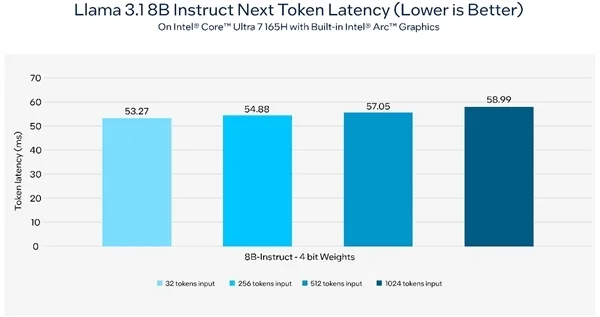
在配备内置Intel锐炫显卡的Intel酷睿Ultra 7 165H AI PC上,Llama 3.1推理的下一个token延迟
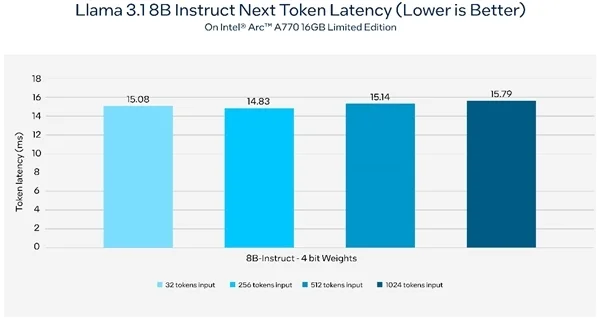
在使用Intel锐炫A770 16GB限量版显卡的AI PC上,Llama 3.1推理的下一个token延迟
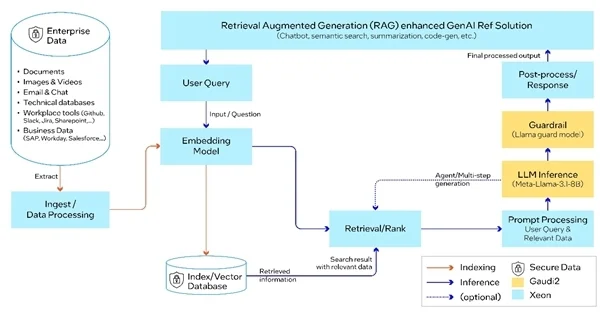
基于Llama 3.1的端到端RAG流水线,由Intel Gaudi 2加速器和至强处理器提供支持
【来源:快金沙手机网投老品牌值得信赖 】















