GPT-4o 自发布以来,支持端到端实时多模态成为国内外大模型厂商纷纷跟进的新方向,先是AI初创公司 Character.AI 表示其已经推出了一项通话功能,允许用户与其人工智能角色进行语音对话,并支持多种语言。微软 AI CEO Mustafa Suleyman 近日也表示,今年年底,微软的 AI 将拥有实时的语音界面,允许完全动态的交互。人与 AI 的实时音视频互动正在走进现实。
GPT-4o 支持实时语音对话,一方面得益于自身大模型能力的进化,端到端实时多模态模型能够直接处理语音,这与传统的三步骤处理方法(语音识别、语音转文字、文字转语音)相比,响应更加及时。另一方面,通过应用 RTC 技术,实现了语音的实时传输,进一步降低了语音交互的延时,RTC 也成为人与 AI 交互的重要一环。

图:电影《Her》里的剧情正在走进现实
实时语音互动:多模态大模型交互的终极形态
多模态大模型的出现,推动了人与AI交互方式的变革,而语音多模态将是其中的必经之路。现实中人与人的沟通就是以语音为主,视觉其次,视觉的重要性在于信息的丰富度,但是信息浓度和沟通效率还得靠语音。声网在实践中发现,传统的三步骤(STT-LLM-TTS)在应用 RTC 后,响应延时可从4-5秒降低到1-2秒,而在具备端到端实时多模态处理能力后,通过 RTC 技术,大模型实时语音对话的延时可降到几百毫秒内。
从体验上看,RTC 技术的应用让对话式大模型的交互更智能,更具真实感。一方面,低延时的快速响应让人与 AI 的互动更接近人与人之间的实时对话,更自然。另一方面,语音还能识别说话人的情绪、语调,视频能识别人的表情与所处的环境,最终输出更精准、更智能的回答。
可以预见的是,未来基于 AI 的人机界面从键盘、鼠标、触屏到实时对话的变革,语音将是必须走过的进化,实时语音互动也将成为未来对话式多模态大模型交互的终极形态。
大模型实时语音落地 端到端实时处理能力与 RTC 是关键
多模态大模型实时语音对话想要落地,背后面临着一系列的技术难点。首先,对于大模型厂商而言,具备端到端实时语音处理的能力很关键,端到端模型的训练成本极高,尤其是处理语音与视频数据,面临大量计算资源,而计算过程往往会造成延迟,这对实时交互的需求造成了挑战,需要边接收语音边处理和解析,对于很多大模型厂商而言,这意味着需要研发更高效、更快的模型或者优化现有模型的运行效率。
其次,多模态大模型在接入 RTC 后如何保障低延时、流畅的语音交互体验也尤为关键。在GPT-4o 的发布会有一个细节,演示 GPT-4o 的手机插着一根网线,工程师 Mark 解释此举是为了保持网络的一致性,这也反应了一个事实,GPT-4o 的演示是在固定设备、固定网络和固定物理环境下进行,以确保低延时。而在实际应用场景中,用户的设备通常无法一直插着网线,这就对大模型实时语音对话中的低延时传输、网络优化等提出了考验。

图:GPT-4o的工程师 Mark 解释手机为啥要插网线
多模态大模型中实时语音交互的核心路径大致如下:
1、首先,语音输入经过 RTC 传输到服务器,服务器端的多模态大模型接收到语音后开始预处理,这里的预处理主要包含了音频的3A,例如语音的降噪、增益控制、回声消除等操作,使得后续的语音识别更加准确,让大模型更能听懂用户说的话;
2、随后,预处理的语音数据送入模型进行语音识别和理解,系统再通过模型生成回应,这其中还需要通过语音合成技术转换为语音信号;
3、最后,语音数据通过 RTC 传输到用户端,完成一次完整的语音交互。
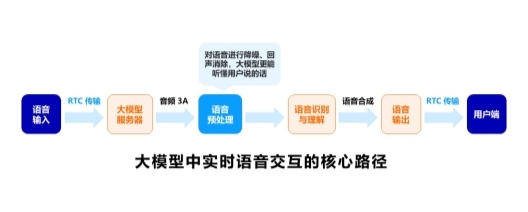
图:大模型中实时语音交互的流程示例
整个语音交互过程中为了达到最低的延迟,很多环节需要进行优化。例如:
· 低延时传输:大模型输入、输出的音视频数据,需要做到低延时传输,以便大模型快速收到语音,生成回复后立即传递给用户,这其中可能还涉及跨国链路的传输,更考验延时;
· 网络优化:网络出现波动后会导致抖动、丢包等问题,实时语音对话就会产生卡顿、延迟高等现象,需要 RTC厂商采用有效的网络优化策略,抗弱网传输等;
· 多设备兼容性:现实场景中由于用户硬件设备的差异,不同的设备可能对于语音处理效果产生影响,性能相对差一些的设备可能会产生更高的延时,需要 RTC SDK 做到海量设备的兼容性,提供统一的低延时传输。
声网构建低延时、流畅的大模型实时音视频互动体验
声网一直在探索 RTC 与 AI 的结合,针对 STT-LLM-TTS 传统三步骤的大模型,声网的 AIGC+RTC方案可以将大模型的语音对话延时降低在2s 以内,并通过AI VAD、AGC、AINS 等实现语义完整性判断,支持随时打断,提高对话体验。
在端到端实时语音多模态的趋势下,声网也推出了实时多模态解决方案,帮助大模型构建实时音视频互动的能力,并实现几百毫秒的超低延时对话体验。
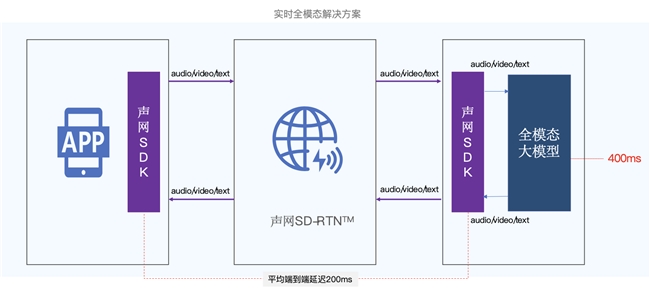
图:声网实时多模态解决方案
术业有专攻,声网基于在 RTC 领域日积月累的深耕细作以及自建的实时传输网络 SD-RTN™,可以做到全球端到端的网络优质传输,有效的解决大模型实时音视频互动中存在的技术难点。
全球端到端延时平均200ms:声网自研的 SD-RTN™ 实时传输网络覆盖了全球200多个国家与地区,音视频的全球端到端延迟平均达到200ms。同时,声网还通过优化网络传输协议和算法,进一步降低音视频传输的延迟,提供超低延时的大模型实时音视频互动体验。
智能路由与抗弱网传输:在大模型实时语音交互中,网络的波动会让交互体验大打折扣。声网 RTC SDK 采用的智能路由技术,能够根据用户的网络状况自动选择最优的网络路径,确保通话的稳定性和流畅性。声网还拥有一套抗弱网传输与抗丢包算法,结合网络探测(如延时估计、带宽估计等)、抗丢包技术、自适应jitter buffer、网络拥塞控制策略等,为用户在各种网络环境下提供流畅的互动体验。
30000+终端机型适配:由于不同的设备可能对于语音处理效果产生影响,声网的 RTC SDK 支持 30000+终端机型适配,中低端机型覆盖广,帮助大模型厂商解决了多设备兼容性的后顾之忧。
此外,围绕大模型的实时互动体验声网还有很多其他优势,例如前文中提到大模型在接收到语音后开始预处理,包含背景声降噪、回声消除等。声网拥有行业领先的音频3A能力,AI降噪强力抑制100+突发噪声,兼顾语音无损伤与混响抑制。AI 回声消除强力抑制非线性回声,还原本来音质,让大模型更能听懂人的对话。
对话式多模态大模型 推动 AI 应用场景爆发
随着多模态大模型能力的进化,AIGC 应用场景将迎来爆发,RTC 技术的接入将推动当下较常见的 AI口语老师、AI客服、AI社交陪聊等场景的 AI 交互体验进一步升级,学生的学习效率更高,社交陪聊场景的娱乐性与沉浸感也进一步增强。

同时,在游戏社交、AI分身、实时语音翻译等场景,对话式多模态大模型也大有可为。例如,在狼人杀、谁是卧底等场景,AI NPC 角色虽然已经在应用,但是 AI 的痕迹还是较为明显。在大模型具备实时语音交互能力后,谁是卧底中的 AI 角色可以做到快速的推理并发言,再搭配语音仿真技术,有望做到 AI 角色的以假乱真。
实时语音翻译:GPT-4o 的发布会演示了实时语音翻译的功能,在英语和意大利语之间无缝转换,据介绍ChatGPT 目前已能够处理50种不同的语言。业内很多人士认为,未来随着大模型实时语音翻译功能的落地,未来可能会取代 Google 翻译与同声传译。
如您想进一步了解声网的实时多模态解决方案,或者想与我们进一步探讨端到端实时多模态大模型,可在声网公众号找到这篇文章扫描底部的二维码。















