关于CUDA在AI行业的影响力,这无需多言,在半导体行业观察之前的诸多文章中,我们也有讲述。
外媒HPCwire之前也曾直言,GenAI 和 GPU 与 Nvidia 的合作并非偶然。Nvidia 一直认识到需要工具和应用程序来帮助其市场增长。他们为 Nvidia 硬件创建了非常低的获取软件工具(例如 CUDA)和优化库(例如 cuDNN)的门槛。
确实,Nvidia 被称为一家硬件公司。但正如 Nvidia 应用深度学习研究副总裁 Bryan Catanzaro 所说,“很多人不知道这一点,但 Nvidia 的软件工程师比硬件工程师还多。”Nvidia 围绕其硬件建立了强大的软件“护城河”。
虽然 CUDA 不是开源的,但它是免费提供的,并且由 Nvidia 牢牢控制。虽然这种情况让 Nvidia 受益(理所当然。他们在 CUDA 上投入了时间和金钱),但对于那些希望通过替代硬件抢占部分 HPC 和 GenAI 市场的公司和用户来说,这带来了困难。
不过,最近又有一个方案跃跃欲试。
SCALE,横空出世
如Phoronix所说,为了突破CUDA护城河,现在已经有各种努力,比如 HIPIFY 帮助将 CUDA 源代码转换为适用于 AMD GPU 的可移植 C++ 代码,然后是之前由 AMD 资助的ZLUDA,允许 CUDA 二进制文件通过 CUDA 库的直接替换在 AMD GPU 上运行。
但现在又出现了一个新的竞争者:SCALE。SCALE 现已作为 GPGPU 工具链公开,允许 CUDA 程序在 AMD 图形处理器上本地运行。
据介绍,SCALE 由英国公司 Spectral Compute 历时七年打造。SCALE 是 CUDA 的“洁净室”(clean room)实现,它利用一些开源 LLVM 组件,同时形成一种解决方案,无需修改即可本地编译适用于 AMD GPU 的 CUDA 源代码。
与其他仅通过转换为另一种“可移植”语言或涉及其他手动开发人员步骤来帮助代码转换的项目相比,这是一个巨大的优势。
SCALE 可以按原样使用 CUDA 程序,甚至可以处理依赖于 NVPTX 汇编的 CUDA 程序。SCALE 编译器也是 NVIDIA nvcc 编译器的替代品,并且具有“模拟”(impersonates)NVIDIA CUDA 工具包的运行时。
SCALE 已成功通过 Blender、Llama-cpp、XGboost、FAISS、GOMC、STDGPU、Hashcat 甚至 NVIDIA Thrust 等软件的测试。Spectral Compute 一直在 RDNA2 和 RDNA3 GPU 上测试 SCALE,并在 RDNA1 上进行基本测试,而 Vega 支持仍在进行中。
从本质上讲,SCALE 是一个兼容 nvcc 的编译器,它可以编译 AMD GPU 的 CUDA 代码、AMD GPU 的 CUDA 运行时和驱动程序 API 的实现,以及开源包装器库,后者又与 AMD 的 ROCm 库交互。
例如,虽然 ZLUDA 是由 AMD 悄悄资助的,但 Spectral Compute表示,他们自 2017 年以来一直通过其咨询业务资助这一开发。SCALE 唯一直接的缺点是它本身不是开源软件,但至少有一个可供用户使用的免费版本许可证。
据官方的文件介绍,SCALE 是一个 GPGPU 编程工具包,允许 CUDA 应用程序为 AMD GPU 进行本地编译。SCALE 不需要修改 CUDA 程序或其构建系统,而对更多 GPU 供应商和 CUDA API 的支持正在开发中。
从构成上看,SCALE 包括:
1 一个nvcc兼容编译器,能够为 AMD GPU 编译 nvcc-dialect CUDA,包括 PTX asm。
2 针对 AMD GPU 的 CUDA 运行时和驱动程序 API 的实现。
3 开源包装器库(wrapper libraries )通过委托给相应的 ROCm 库来提供“CUDA-X”API。这就是和等库的cuBLAS处理cuSOLVER方式。
与其他解决方案不同的是,SCALE并不提供编写 GPGPU 软件的新方法,而是允许使用广受欢迎的 CUDA 语言编写的程序直接为 AMD GPU 进行编译。同时,SCALE 旨在与 NVIDIA CUDA 完全兼容,因为他们认为用户不必维护多个代码库或牺牲性能来支持多个 GPU 供应商。
最后,开发方表示,SCALE 的语言是NVIDIA CUDA 的超集,它提供了一些可选的语言扩展 ,可以让那些希望摆脱的用户更轻松、更高效地编写 GPU 代码nvcc。
总结而言,与其他跨平台 GPGPU 解决方案相比,SCALE 有几个关键创新:
1 SCALE 接受原样(as-is)的 CUDA 程序。无需将它们移植到其他语言。即使您的程序使用内联 PTX 也是如此asm。
2 SCALE 编译器接受与相同的命令行选项和 CUDA 方言nvcc,可作为替代品。
3 “模拟” NVIDIA CUDA 工具包的安装,因此现有的构建工具和脚本就可以cmake 正常工作。
具体到硬件支持方面,在特定硬件支持方面,以下 GPU 现在会得到支持和测试:
AMD GFX1030(Navi 21、RDNA 2.0)
AMD GFX1100(Navi 31、RDNA 3.0)
以下 GPU 目标已经过临时手动测试并且“似乎有效”:
AMD GFX1010
AMD GFX1101
Spectral Compute 正在致力于支持 AMD gfx900(Vega 10、GCN 5.0),并且可能会针对其他 GPGPU。
当然,如前所说,他们会支持更多的GPU。
突破CUDA,AMD和Intel的做法
作为GPU的另一个重要玩家,AMD也正在通过各种各样的办法跨越CUDA护城河。
在HPCwire看来,替换Nvidia 硬件意味着其他供应商的 GPU 和加速器必须支持 CUDA 才能运行许多模型和工具。AMD 也已通过HIP CUDA 转换工具实现了这一点。据了解,这是一种 C++ 运行时 API 和内核语言,可让开发人员从单一源代码为 AMD 和 NVIDIA GPU 创建可移植的应用程序。需要强调一下的是,HIP 不是 CUDA,它原生基于AMD ROCm,即 AMD 的 Nvidia CUDA 等效产品。
AMD 还提供了开源HIPIFY转换工具。HIPIFY 可以获取 CUDA 源代码并将其转换为 AMD HIP,然后可以在 AMD GPU 硬件上运行。的归纳然,这同样是其 ROCm 堆栈的一部分。
AMD同时还和第三方开发者共同合作,推出了ZLUDA项目,从而让AMD的GPU也可以在英伟达CUDA应用上运行。ZLUDA 在 AMD GPU 上运行未经修改的二进制 CUDA 应用程序,性能接近原生。ZLUDA 被认为是 alpha 质量,已确认可与各种原生 CUDA 应用程序(例如 LAMMPS、NAMD、OpenFOAM 等)配合使用。直到最近,AMD 还悄悄资助了 ZLUDA,但赞助已经结束。该项目仍在继续,因为最近有人提交了代码库。
来到英特尔方面,他们也做了很多尝试。
在2023年9月的一个演讲中,英特尔首席技术官 Greg Lavender 建议,我们应该构建一个大型语言模型 (LLM),将其转换为可以在其他 AI 加速器上运行的东西——比如它自己的 Gaudi2 或 GPU Max 硬件。“我向所有开发人员提出一个挑战。让我们使用 LLM 和 Copilot 等技术来训练机器学习模型,将所有 CUDA 代码转换为 SYCL”,Greg Lavender 说。
据介绍,SYCL在异构框架中跨 CPU、GPU、FPGA 和 AI 加速器提供一致的编程语言,其中每个架构都可以单独或一起使用进行编程和使用。SYCL 中的语言和 API 扩展支持不同的开发用例,包括开发新的卸载加速或异构计算应用程序、将现有的 C 或 C++ 代码转换为与 SYCL 兼容的代码,以及从其他加速器语言或框架迁移。
具体而言,SYCL(或者更具体地说是 SYCLomatic)是一个免版税的跨架构抽象层,为英特尔的并行 C++ 编程语言提供支持。
简而言之,SYCL 处理了大部分繁重的工作(据称高达 95%),即将 CUDA 代码移植到可以在非 Nvidia 加速器上运行的格式。但正如您所预料的那样,通常需要进行一些微调和调整才能让应用程序全速运行。
“如果你想要充分利用英特尔 GPU(而不是 AMD GPU 或 Nvidia GPU),那么你就必须采取一些措施,无论是通过 SYCL 的扩展机制,还是简单地构建代码,”英特尔软件产品和生态系统副总裁 Joe Curley解释道。
与此同时,由英特尔、谷歌、Arm、高通、三星和其他金沙手机网投老品牌值得信赖 公司组成的一个团体正在开发一款开源软件套件,以防止人工智能开发人员被 Nvidia 的专有技术所束缚,从而使他们的代码可以在任何机器和任何芯片上运行。
这个名为“统一加速基金会”(UXL:Unified Acceleration Foundation )的组织告诉路透社,该项目的技术细节应该会在今年下半年达到“成熟”状态,但最终发布目标尚未确定。该项目目前包括英特尔开发的OneAPI开放标准,旨在消除对特定编码语言、代码库和其他工具的要求,避免开发人员必须使用特定架构,例如 Nvidia 的 CUDA 平台。具体可以参考之前的文章《打破CUDA霸权》。
但是,这似乎还不够,更多厂商也在行动。
还有更多方案
如大家所知,在 HPC 领域,支持 CUDA 的应用程序统治着 GPU 加速的世界。使用 GPU 和 CUDA 时,移植代码通常可以实现 5-6 倍的加速。(注意:并非所有代码都能实现这种加速,有些代码可能无法使用 GPU 硬件).
然而,在 GenAI 中,情况却大不相同。
最初,TensorFlow 是使用 GPU 创建 AI 应用程序的首选工具。它既适用于 CPU,也可通过 GPU 的 CUDA 加速。这种情况正在迅速改变。TensorFlow 的替代品是 PyTorch,这是一个用于开发和训练基于神经网络的深度学习模型的开源机器学习库。Facebook 的 AI 研究小组主要开发它。
AssemblyAI的开发者教育者 Ryan O'Connor在一篇博客文章中指出,热门网站HuggingFace(用户只需几行代码即可下载并把经过训练和调整的最新模型合并到应用程序管道中)中 92% 的可用模型都是 PyTorch 独有的。
此外,如图一所示,机器学习论文的比较显示出了明显的倾向于使用 PyTorch 而远离 TensorFlow 的趋势。
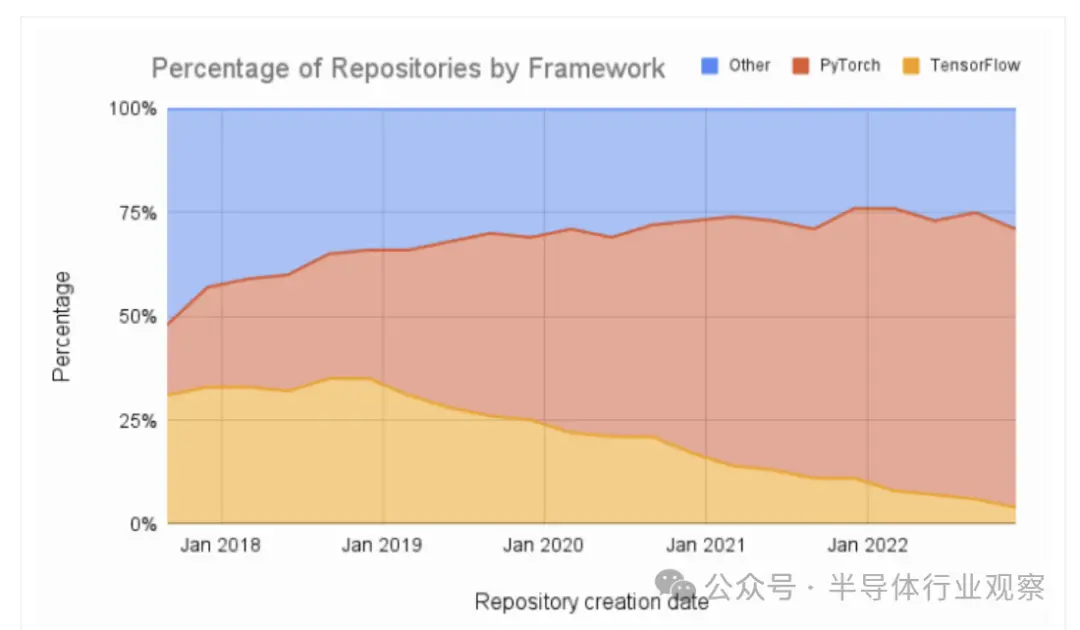
当然,PyTorch 的底层是 CUDA 调用,但这不是必需的,因为 PyTorch 将用户与底层 GPU 架构隔离开来。还有一个使用 AMD ROCm的PyTorch版本,AMD ROCm 是用于 AMD GPU 编程的开源软件堆栈。跨越 AMD GPU 的 CUDA 护城河可能和使用 PyTorch 一样简单。在之前的文章《CUDA正在被赶下神坛》中,有谈了PyTorch对CUDA的影响,
对于这些方案,大家都是怎么看啊?
【来源:半导体行业观察】















