3 月 7 日消息,阿里巴巴研究团队近日推出了 AtomoVideo 高保真图生视频(I2V,Image to Video)框架,旨在从静态图像生成高质量的视频内容,并与各种文生图(T2I)模型兼容。

IT之家总结 AtomoVideo 特性如下:
高保真度:生成的视频与输入图像在细节与风格上保持高度一致性
运动一致性:视频动作流畅,确保时间上的一致性,不会出现突兀的跳转
视频帧预测:通过迭代预测后续帧的方式,支持长视频序列的生成
兼容性:与现有的多种文生图(T2I)模型兼容
高语义可控性:能够根据用户的特定需求生成定制化的视频内容
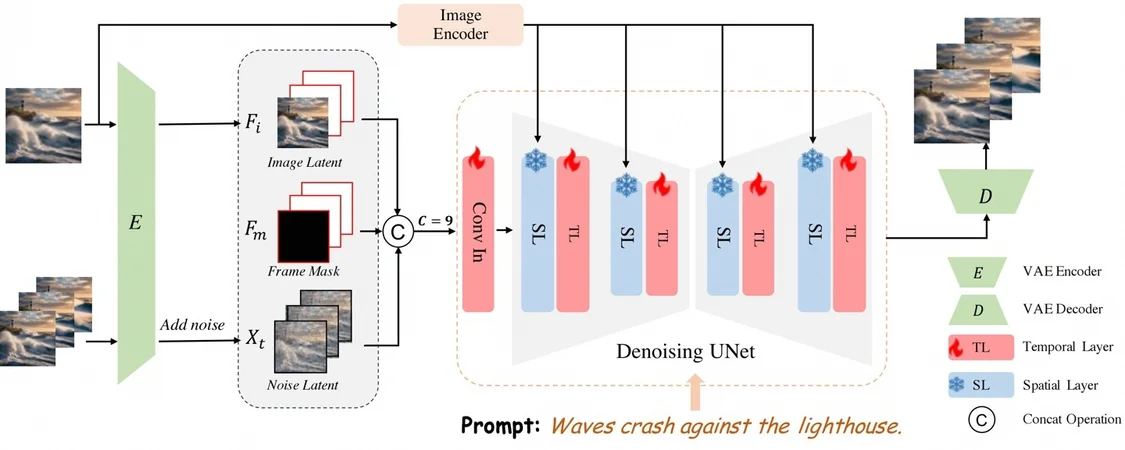
AtomoVideo 使用预先训练好的 T2I 模型为基础,在每个空间卷积层和注意力层之后新添加一维时空卷积和注意力模块,T2I 模型参数固定,只训练添加的时空层。由于输入的串联图像信息仅由 VAE 编码,代表的是低层次信息,有助于增强视频相对于输入图像的保真度。同时,团队还以 Cross-Attention 的形式注入高级图像语义,以实现更高的图像语义可控性。
目前,该团队只发布了 AtomoVideo 的论文及演示视频,并未提供在线体验地址。同时官方开设了 GitHub 账户,但仅用作官方网站托管,并未上传任何相关代码。
【来源:IT之家】















